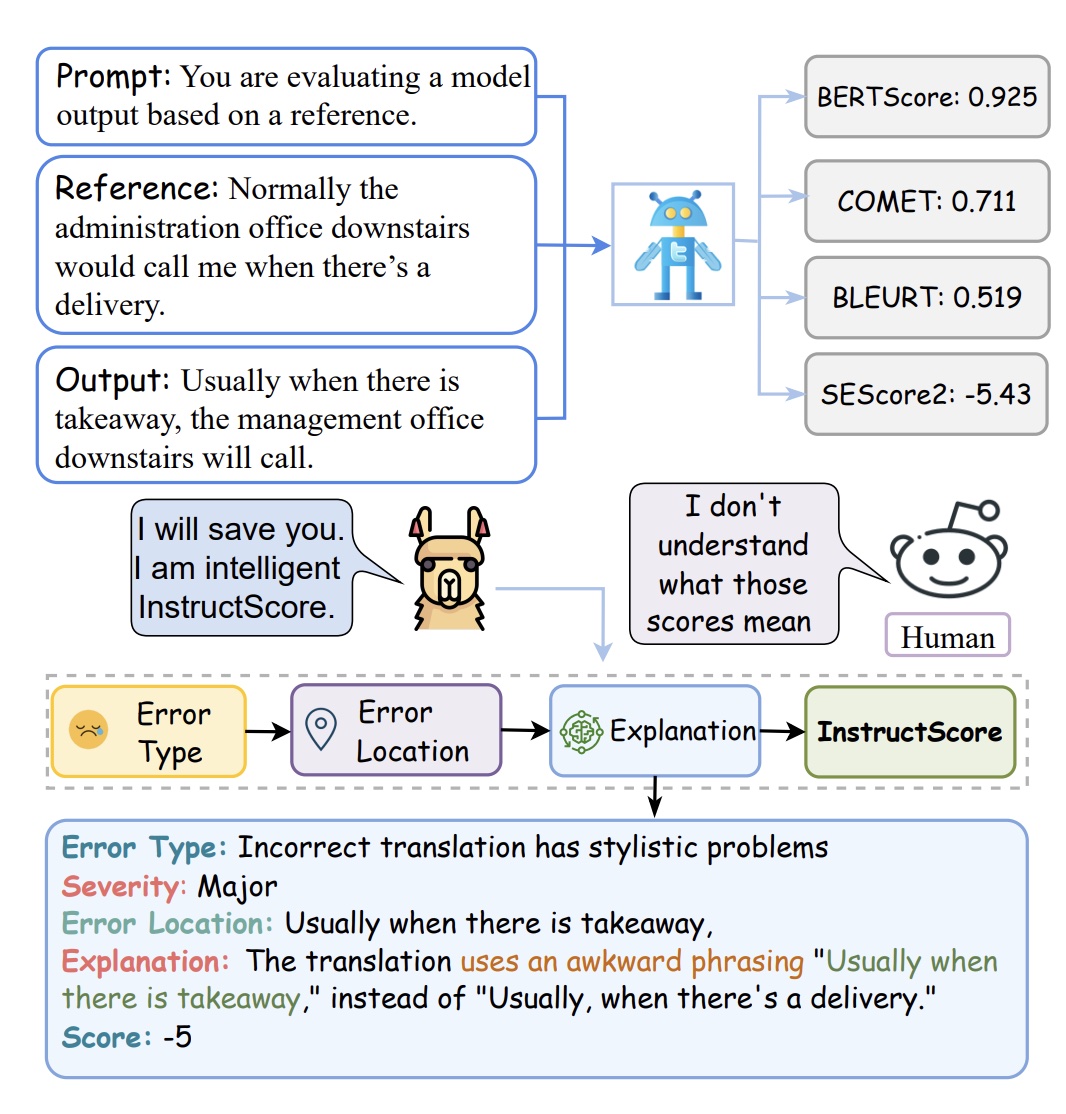
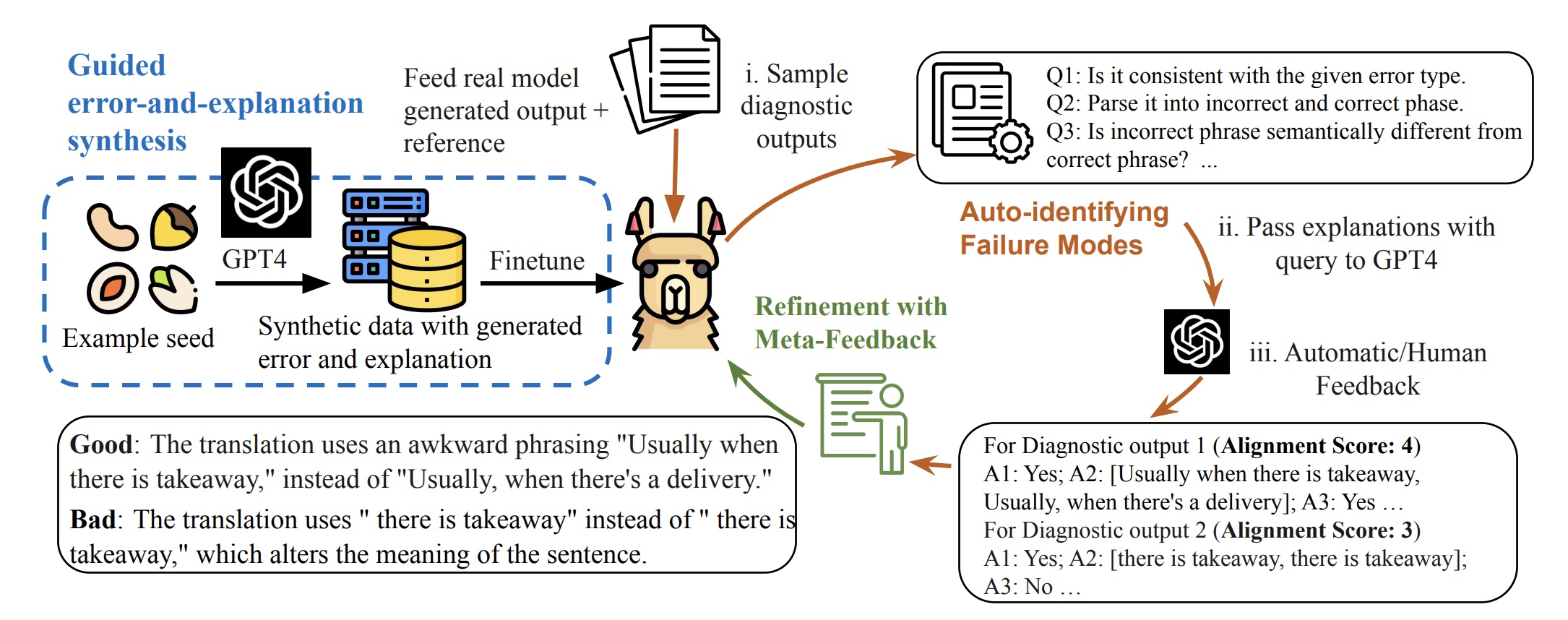
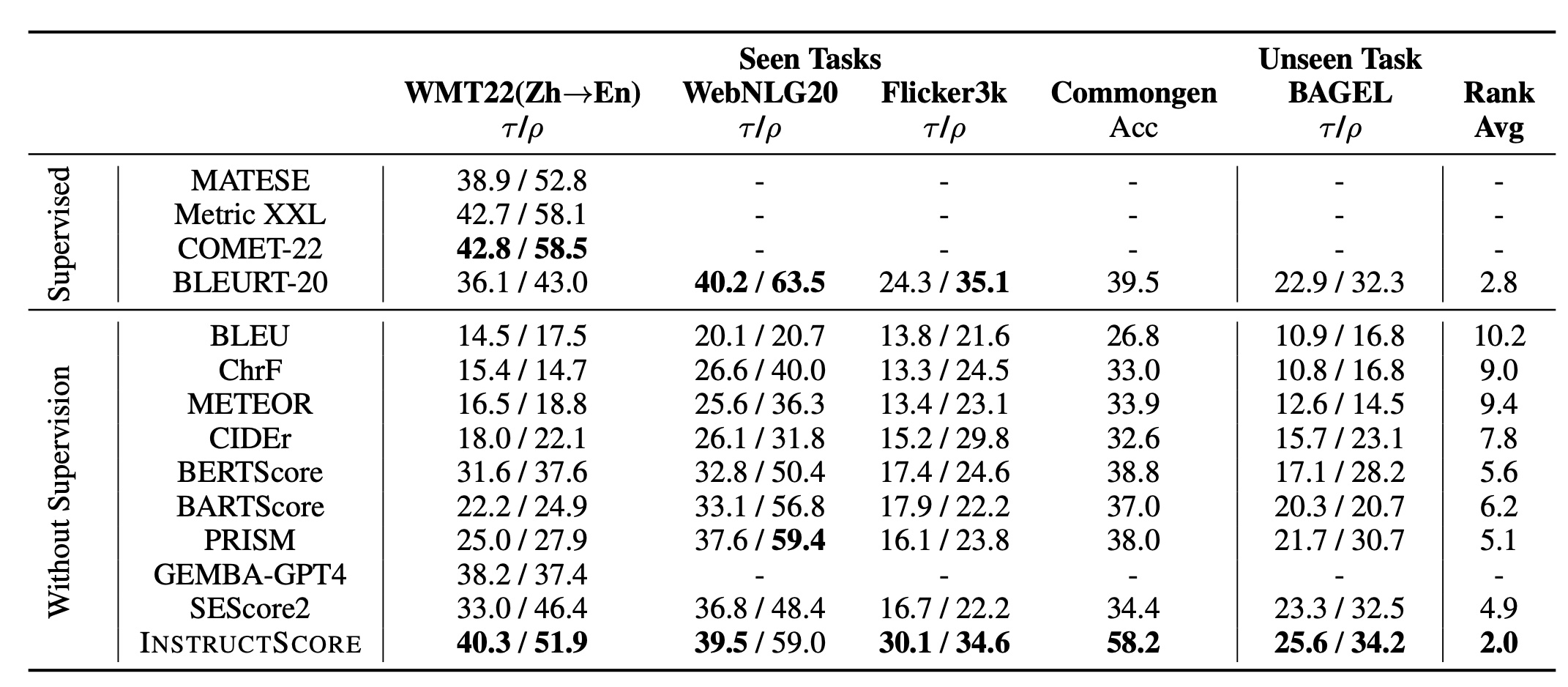
Automatically evaluating the quality of language generation is critical. Although recent learned metrics show high correlation with human judgement, these metrics can not explain their verdict or associate the scores with defects in generated text. To address this limitation, we present InstructScore, an explainable evaluation metric for text generation. By harnessing both explicit human instruction and the implicit knowledge of GPT-4, we fine-tune a text evaluation metric based on LLaMA, producing both a score for generated text and a human readable diagnostic report. We evaluate InstructScore on a variety of generation tasks, including translation, captioning, data-to-text and commonsense generation. Experiments show that our 7B model surpasses all other unsupervised metrics, including those based on 175B GPT-3 and GPT-4. Surprisingly, our InstructScore, even without direct supervision from human-rated data, achieves performance levels on par with state-of-the-art metrics like COMET22, which were fine-tuned on human ratings.